Die SQL Server 2016 In-Memory Evolution
– Von Row-Store zu Columnstore zu In-Memory Operational Analytics
Der SQL Server 2016 ist da, und damit nun auch die „Version 2“ der In-Memory OLTP Engine, wenn man so will.
- Was hinter der im SQL Server 2014 eingeführten In-Memory Engine von SQL Server steckt, habe ich auf diversen internationalen Konferenzen und in der IX bereits 2014 vorgestellt. Zu einem Blog-Artikel bin ich leider bisher nicht gekommen.
In diesem Artikel möchte ich die Neuerungen und Verbesserungen beleuchten, an denen Microsoft die letzten 2 Jahre gearbeitet hat, und die viel auf Kundenfeedback zurückzuführen sind. Feedback, welches in einem großen Maße noch aus „nicht umsetzbar, weil dies und dies fehlt“ bestand.
Und eines kann ich vorwegnehmen: in meinen Augen hat Microsoft die überwiegende Anzahl an Blockern adressieren können.
Das heißt, In-Memory ist für jeden mindestens eine Evaluierung wert, und in fast allen Datenbank-Projekten finden sich Strukturen, die man In-Memory eleganter lösen kann. – Ok, nicht für ganz jeden, denn dieses Feature ist leider der Enterprise-Edition vorbehalten.
Die wichtigsten Neuerungen für memory optimierte Tabellen sind:
Man kann nun sowohl Unique Indexe als auch Fremdschlüssel-Constraints definieren. Letztere sind nur zwischen memory-optimierten Tabellen möglich (und nicht zwischen Disk-/Page-basierten und memory-optimierten Tabellen), und müssen sich immer auf den Primärschlüssel beziehen – der Verweis auf Unique Indexe ist nicht möglich.
Auch sind nun NULL-Werte in Nicht-Unique Indexen zulässig (Anders als bei Disk-basierten Tabellen nicht in Unique-Indexen!).
Ebenfalls sehr wichtig ist die Unterstützung aller Codepages und von Nicht-Unicode-Daten sowie die Verschlüsselung der memory-optimierten Daten mit TDE (ergo nicht im Arbeitsspeicher selber sondern der Daten, die auf der Festplatte abgelegt werden). *1
Das waren in meinen Augen die häufigsten Blocker in Projekten, in denen In-Memory evaluiert wurde, da es dafür kaum praktikable Workarounds gab.
*1 Daten-Verschlüsselung mit den ENCRYPTION-Funktionen in SQL Server wird nicht unterstützt – das gilt auch für die neue Always Encrypted Technologie und Dynamic Data Masking.
Row-Level Security von SQL Server 2016 wird aber unterstützt. Die Prädikate und Funktionen, müssen dann nativ kompiliert werden. Sehr cool, wenn ihr mich fragt.
Eine weitere Einschränkung ist mit der Möglichkeit, Memory-optimierte Tabellen im Nachhinein zu ändern, entfallen. Unterstützt ist das Hinzufügen, Entfernen, und Ändern von Spalten und Indexen im Nachhinein. Anstelle CREATE/ALTER/DROP Index muss hier nun ALTER TABLE verwendet werden, da bei Memory optimierten Tabellen Indexe Teil der Tabellen-Definition sind (und in Gesamtheit kompiliert werden). Besonders wichtig hierbei ist, dass man darüber nun auch den Bucket-Count von Hash-Indexen ändern kann, der sich naturgemäß ja im Betrieb sehr stark ändern kann mit der Zeit. So sieht das im Code an einem Beispiel aus:

Statistiken können auch mit SAMPLE anstelle FULLSCAN aktualisiert werden, und vor allem auch automatisch.
Datentypen: LOB-Datentypen wie varchar/varbinary(max) werden unterstützt, und werden „off-row“ gespeichert.
Wichtige, neu unterstützte T-SQL Funktionalitäten innerhalb von Natively compiled Stored Procedures und, ganz neu, Functions sind: die OUTPUT-Klausel, UNION und UNION ALL, DISTINCT, OUTER JOINs, Unterabfragen.
Außerdem können nativ kompilierte Prozeduren nun auch mit ALTER PROCEDURE verändert werden. Dadurch werden sie naturgemäß im letzten Schritt in der neuen Form kompiliert abgelegt. Um für den Fall von geränderten Statistiken einen neuen Ausführungsplan zu ermöglichen, kann man nun auch sp_recompile gegen nativ kompilierte Prozeduren (und Funktionen) ausführen.
Auch an der Performance wurde weiter geschraubt. So können memory-optimierte Tabellen und Hash-Indexe jetzt (im InterOP Mode) parallel gescannt werden. Im IO Bereich wurde der gesamte Checkpoint-Prozess überarbeitet und die Datenfiles können nun mit multiplen Threads geschrieben und gelesen werden, wodurch sich der Durchsatz fast auf ein zehnfaches erhöhen kann (wenn das IO-Subsystem da mithält).

Columnstore-Technologie
Was hat sich eigentlich in der anderen, seit 2012 im SQL Server integrierten Storage-Engine „Vertipaq“ mit den Columnstored Indexen getan? Diese sind ja ebenfalls Main-memory optimiert, jedoch mit ganz anderem Ziel: Speicherplatzoptimierung und effiziente OLAP-Style-Queries.
Die Neuerungen hier sind sehr essentiell:
Beide Columnstore Index Typen, Clustered und Nonclustered, sind nun aktualisierbar! Außerdem lassen sich Columnstore Indexe nun mit weiteren traditionellen btree-Indexen ergänzen. Das ist wichtig, weil ja nicht jede Abfrage wirklich von der Columnstore-Speicherform profitiert. Dieser Zugewinn an Flexibilität ist ein entscheidender Vorteil gegenüber den bisherigen Releases und kann gar nicht genug betont werden.
Und noch etwas ist nun möglich: Nonclustered Columnstore können mit einem Filter erstellt werden.
Mit diesen neuen Techniken lässt sich zum Beispiel folgendes Problem lösen:
Eine Tabelle mit Verkaufstransaktionen wird im Sekundentakt durch kleine Inserts gefüllt.
Nebenbei möchte man aber auch diverse Berichte mit Tages- und Tageszeitaggregationen bereitstellen. So aktuell wie möglich natürlich. Das Problem ist hierbei typischerweise, dass man sich hier entscheiden muss zwischen Indexen für alle Berichtsabfragen und denen, die minimal notwendig sind für etwaige Updates. Inserts benötigen ja für sich gesehen keine Indexe. Durch diese Kombination entstehen die mit vielen Indexen überfrachteten OLTP-Tabellen, die ich bei meinen Einsätzen oft entdecke und die es dann gilt, „wegzuoptimieren“.
Mit der Möglichkeit einen Nonclustered Columnstore Index zusätzlich zu dem Clustered Index anzulegen, spart man nicht nur Indexe, (denn der Columnstore-Index kann ja jede nötige Spalte abdecken) sondern mit einem geschickt gesetzten Filter kann man auch den Index-Overhead vermeiden, der sonst die eigentlich wichtigeren Inserts treffen würde.
Die Vermischung aus OLTP- und OLAP-Abfragen sind eines der typischsten Probleme von Datenbanken, und diese neuen Möglichkeiten sind daher einfach ein Traum für Datenbank-Architekten. So sieht das im Code aus:

40% Performance-Verbessrung im TPC-H Benchmark
Diese Verbesserungen haben den SQL Server 2016 im TPC-H Benchmark performance-technisch mit fast 40% mehr QphH (Query-per-Hour Performance Metric) am SQL Server 2014 vorbeiziehen lassen. Auf dem Screenshot kann man sehen, dass der Benchmark am 9.3.2016 eingesendet wurde, und auch wirklich auf derselben Hardware wie am 1.5.2015 unter SQL Server 2014 erzielt wurde.

Weitere wichtige Verbesserungen für Columnstore sind die Unterstützung des SNAPSHOT Isolation Level (und RCSI), was besonders für Read-Only Replicas von Availability Groups wichtig ist, sowie Online-Defragmentierung und diverse Analyse-Verbesserungen.
Das Highlight: Real-time Operational Analytics & In-Memory OLTP
Das Highlight schlechthin aber ist sicherlich die Kombination aus memory-optimierten Tabellen und ColumnStore Indexen.
Damit werden zwei Features, die für völlig gegensätzliche Abfrage-Typen, OLTP und OLAP, optimiert sind, verschmolzen.
Technik
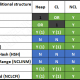
Technisch kommt ein Clustered Columnstore Index zum Einsatz. Dieser lässt, wie man in dem Bild sehen kann, den „hot-Bereich“ der Daten aus, um den Overhead durch die doppelte Datenhaltung bei Änderungen bzw. den potentiell schnell aufeinander folgenden Inserts in diesem Bereich zu vermeiden. Zusätzlich zu der implizierten Delta Rowgroup (im Bild: Tail), die durch den memory-optimierten Index abgedeckt wird, gibt es eine „deleted rows table“ für gelöschte Daten. Beide Bereiche werden nach dem für Columnstore Indexe standardmäßigen Schwellwert von 1 Million Zeilen asynchron komprimiert/dem CCI hinzugefügt.
An dieser Stelle noch ein Hinweis: auch die maximale Datenmenge, die pro Datenbank in (durable) memory-optimierten Tabellen gehalten werden kann, ist nun entfernt worden! Nach aktuellem Stand der Technik sind unter Windows Server 2016 damit theoretisch bis zu 12 TB (abzgl. einem Maintenance-overhead) in XTP-memory speicherbar!
Von der Struktur her gestaltet sich das so:

Und die Umsetzung in Code sieht so aus:

Im Ergebnis hat man nun das Beste aus beiden Welten: hochperformante Inserts/Updates/Deletes und Singleton-Abfragen, und zugleich hochperformante analytische Abfragen, die mit vielen Millionen Zeilen auf einmal hantieren – und zwar zeitgleich auf derselben Tabelle!

Eine Einschränkung beim Abfragen ist, dass der Columnstore Index auf memory-optimierten Tabellen nur im InterOP-Modus funktioniert – also nicht in nativ kompilierten Prozeduren.
Und da wären wir beim letzten Thema:
Offene Punkte, fehlende Feature-Unterstützung Es gibt natürlich auch jetzt noch eine ganze Reihe an Features, die durch die über jahrzehntelange andauernden Entwicklung der SQL-Sprache in den SQL Server übernommen wurde, aber eben noch nicht in die neue XTP-Engine gelangt sind. Das liegt nicht nur daran, dass diese „einfach neu“ ist, sondern auch, dass durch die völlig andere Architektur dieser radikal auf In-Memory getrimmten Engine einige wesentliche Unterschiede zu den althergebrachten Datenbank-Engines bestehen.
Folgende Features vermisse ich persönlich noch am meisten:
- DBCC CHECKDB/CHECKTABLE für memory optimierte Tabellen
- CASE-Statement
- Filtered Indexe
- CTEs
- Replikation
- OFFSET-Operator
- Ranking Funktionen
- DDL Trigger für CREATE/DROP TABLE und CREATE/DROP PROCEDURE
- TRUNCATE TABLE
- DATA_COMPRESSION
- Datentyp datetimeoffset
Die vollständige Liste befindet sich hier:
Transact-SQL Constructs Not Supported by In-Memory OLTP
Call to Action
Auch wenn die Liste an fehlendem Feature/Funktionssupport immer noch recht lang ist – die wenigsten nutzen wirklich all diese Features voll aus. Und für die meisten dieser übriggebliebenen „Blocker“ gibt es eigentlich recht gute Workarounds, sei es in Form einer anderen Architektur oder Code-technisch. Man muss auch bedenken, dass die In-Memory Tabellen nicht für alle Szenarien überhaupt Sinn machen, sondern eher für die Top-belasteten Tabellen Sinn machen. Und da sollte man sich ohnehin bereits etwas Mühe beim Design gemacht haben.
Generell bin ich der festen Meinung, dass sich in fast jedem Datenbankprojekt einige Stellen finden werden, die von In-Memory Funktionen profitieren können.
Warum kann ich das so sicher sagen?
Bereits seit SQL 2014 gibt es die Möglichkeit neben Memory-optimierten Tabellen auch Memory- optimierten Tabellen Variablen zu verwenden. Und mit diesen lassen sich wiederum viele Temptable-Konstrukte ablösen.
Nun werden dadurch nicht unbedingt gleich ganze Applikationen performanter, aber es ist ein Anfang, sich mit In-Memory Codetechnisch auseinanderzusetzen und langsam aber sicher damit zu programmieren. Ein weiterer „Quick-Win“ ist oft in Datawarehouse-Architekturen im sogenannten „Staging-Bereich“ zu finden, wie er gerade in traditionellen DW-Systemen häufig zum Einsatz kommt.
Und über diese „Einfallstore“ ist man ganz schnell in der „In-Memory-Welt“ angekommen.
Cu In-Memory
Andreas
PS:
If you are in India in August and want to advance your skills in those new technologies there is still a chance to get a seat in the Precon „Present and Future: In-Memory in SQL Server – from 0 to Operational Analytics Master“ at SQL Server Geeks Summit in Bangalore on August 10.

Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!