Schema-Design für SQL Server: Empfehlungen für Schema-Design mit Sicherheit im Blick
Einleitung
In diesem Artikel greife ich ein Thema auf, welches ich schon seit vielen Jahren immer wieder in Seminaren, bei Konferenzen und auch in Foren versuche zu vermitteln: Schema-Design. Mit Schema ist hierbei nicht das Datenbankschema mit seinem Tabellen-Design gemeint, sondern die „Datenbank-Objekt-Schemas“, die auch als Namensraum beschrieben werden.
Seit dem Release von SQL Server 2005, nun immerhin über 10 Jahre her, liegt es mir besonders am Herzen, Nutzer darin zu schulen, wie man Schemas richtig verwendet. Eigentlich ist das auch gar nicht besonders schwierig. So, wie ein Entwickler/Architekt, sich für das ER-Diagramm und spätere Tabellendesign mit den Geschäftsprozessen auseinandersetzen muss, muss man sich für das Schema-Design mit den Datenbank-Zugriffs-Prozessen auseinandersetzen. Leider jedoch sehe ich auch heute noch jede Woche Datenbanken, die nur das „dbo“ Schema zu kennen scheinen.
Ich gebe zu, der Umfang an Informationen zu diesem Thema ist nicht so umfangreich wie zu den Dauerrennern „Indexing“ und „Performance“. Sicherheits-Härtung ist ein eher lästig empfundener Aufwand, und selten sind Entwickler in solchen Dingen geschult, um die wichtigen Entscheidungen gleich zur Design-Phase zu fällen. Mit diesem Blog-Post, der zugegeben lange überfällig ist, hoffe ich eine gute Referenz schaffen zu können. Denn, zur Entlastung aller Autodidakten, ausgerechnet die bekannte „AdventureWorks“-Datenbank ist alles andere als ein Vorbild in Sachen Schema-Design. Diese Datenbank ist prinzipiell geschaffen, um die neuen Features der SQL Server Versionen seit 2005 demonstrieren zu können, aber nicht immer werden die Konzepte dabei nach Best Practices entwickelt. Zumal das Konzept der Schema-User-Trennung damals noch recht neu war.
Hintergrund-Informationen
Bis SQL Server 2000 waren User und Schemas voneinander abhängig, und man hatte nur 2 Möglichkeiten:
- alle Entwickler legten alle Objekte in das dbo-Schema
- Objekte liegen im Schema mit dem Namen des Entwicklers, also z.B.: „Andreas.Warenkorb“
Der 2. Ansatz war natürlich völlig impraktikabel, abgesehen von Ein-Mann-Entwicklungen. Entwickler waren also mit db_owner(!)-Rechten ausgestattet und dazu angehalten, Objekte bei allen DDL-Befehlen immer mit dbo.Objektname, also als „Two-Part-Name“ zu spezifizieren. Wurde das vergessen, stand plötzlich der Name des Entwicklers vor den Objekten und Kreuz-Referenzen funktionierten dann meist nicht. – Immerhin war der Verursacher dann klar 🙂
Wer das alles nicht beachtete, hatte das Problem, dass er Konten von ehemaligen Entwicklern nicht vom Server löschen konnte, da ihnen ja noch Objekte zugeordnet waren, die dann am Ende fest in der Applikation verankert waren.
Und deshalb hat das Security-Team für den SQL Server 2005 das Schema-Konzept komplett überarbeitet, mit dem Ziel, die Delegierung von Rechten zu vereinfachen. Das dbo-Schema ist im Wesentlichen ein Relikt aus der pre-2005 Welt, welches aus Rückwärts-Kompatibilitätsgründen noch da ist und gleichzeitig als Default-Schema bei der Namensauflösung verwendet wird (ebenfalls wie vorher).
Sinn und Zweck von Datenbank-Schemas
Ich zitiere an dieser Stelle ein Mitglied des Security-Teams: „das Ziel der Trennung von Schemas von Usern war, die Sicherheit zu verbessern – durch die Ermöglichung von Delegierung etc.”
Oder, um das passende Whitepaper „SQL Server Best Practices – Implementation of Database Object Schemas” zu zitieren:
„Ein Schema ist ein eindeutiger Namensraum um die Trennung, Verwaltung und den Besitz von Datenbankobjekten zu erleichtern. Es entfernt die enge Kopplung von Datenbankobjekten und Eigentümern um die Sicherheitsverwaltung von Datenbankobjekten zu verbessern. Database-Objekt-Schemas bieten Funktionalitäten um Anwendungsobjekte innerhalb einer Datenbankumgebung zu kontrollieren und helfen sie zu sichern…“
Soweit zu dem hauptsächlichen Zweck.
Natürlich kann man Schemas auch als Ordnungselement verwenden. Ich möchte sogar einladen dazu, das zu tun. Aber bitte erst an zweiter Stelle, wenn die Sicherheitsgrenzen feststehen.
Im Bild ein Beispiel, in dem mehrere Datenbankprinzipale Objekte in einem gemeinsamen Schema verwenden können:

Negativ-Beispiel
Sehen wir uns einmal die eingangs angesprochenen Schemas in der AdventureWorks-Datenbank an:

Auf den ersten Blick mag das schön „ordentlich“ aussehen. Wenn man jedoch genauer hinsieht und überlegt, wie man dort nun Berechtigungen vergeben soll, sieht es eher chaotisch aus.
In allen Schemas gibt es Tabellen und entweder auch Sichten oder Prozeduren oder beides. Wenn man sich jetzt eine Frontend-Applikation dazudenkt, wo soll diese nun Berechtigungen erhalten?
Dass db_datareader, db_datawriter und eine „selbsterstellte „db_executor“ o.ä. nicht der Maßstab für diesen Artikel sind, ist sicherlich klar. – Das ist aber durchaus ein valider Ansatz für kleinere Datenbanken, mit wenigen Objekten, oder für Datenbanken, deren Objekte alle wirklich gleichermaßen verwendet werden sollen.
KISS-Prinzip: „Keep it simple, stupid”
Für Sichten gibt es die SELECT- Berechtigung, bei Ad-Hoc-CRUD-Abfragen auch INSERT, UPDATE und DELETE. Für Prozeduren genügt die EXECUTE Berechtigung. Berechtigungen können auf Datenbank- Schema- und Objektebene vergeben werden. Und natürlich ist die Schema-Ebene die Ebene, die sich anbieten würde, wenn man verhindern möchte, dass man Berechtigungen auf alle Objekte ohne Einschränkung vergibt, aber auch, wenn man sich nicht mit Einzel-Objekt-Berechtigungen herumschlagen möchte.
Hier ist ein Beispiel aus dem offiziellen MOC-Kurs:

In diesem Beispiel wird das SELECT-Recht auf alle Objekte in dem Schema „Knowledgebase“ vergeben. Angewandt auf unser AdventureWorks-Schema-Design, würde das bedeuten, dass wir SELECT-Rechte auf alle Schemas vergeben müssen, in denen Sichten oder Tabellen liegen – mit Ausnahme derer, wo neben Tabellen lediglich Prozeduren liegen, die auch wirklich alle benötigten Operationen gegen die im selben Schema enthaltenen Tabellen durchführen – was hier auch nicht der Fall ist.
Im Endeffekt wird man SELECT, INSERT, UPDATE, DELETE-Rechte auf alle Schemas vergeben müssen, zuzüglich einiger EXECUTE-Berechtigungen auf das dbo-, HumanResources-, Production- und Sales-Schema.
Viel gewonnen hat man damit nicht.
Ein Anwender kann damit auch an den Prozeduren vorbei auf den Tabellen arbeiten, wenn er eine Direkt-Verbindung zur Datenbank aufgebaut hat.
Schema-Design richtig gemacht
Wie sähe es aus, wenn man es aus der Sicherheitsperspektive richtig macht?
Das ist nicht weiter schwer vorzustellen. SQL Server kennt ja so die “Objekt-Besitzerverkettung” (“Object-Ownership-Chaining”). Schemas haben einen Besitzer und sind Teil der Kette. Das heißt, solange die beteiligten Schemas den selben Besitzer haben, kann man in einem Schema, „Zugriffobjekte“ (Sichten, Prozeduren, Funktionen) halten, und in einem anderen Schema Objekte (Tabellen), auf die man keinen direkten Zugriff erlauben möchte.
Das Prinzip hatte ich 2009 auf dem PASS Summit in Seattle im Vortrag „Securing SQL Server from Inside-Attacks“ „Schema-Ownership-Chaining“ getauft.

Schema-Ownership-Chaining
Man sieht hier in der (leicht modifizierten) Slide, dass ein User keinen direkten Zugriff auf die Tabellen in dem Schema „Data“ hat, sondern nur über Sichten in dem Schema „Access“ (=„Zugriff“ – daher „Zugriffsschema“). Das funktioniert, weil die Schemas und die enthaltenen Objekte denselben Besitzer haben. Hier „dbo“.
Zur SQLRally Nordic, 2012 in Kopenhagen für den Vortrag „SQL Server 2012 Security for Developers“ hatte ich das Konzept noch etwas verfeinert:

Best Practices für Schema-Design
Aus dieser Grafik geht noch besser hervor, dass in dem Schema „App1“ keine Tabellen liegen, sondern nur Zugriffscode in Form von Prozeduren, ggf. Sichten. Daher genügt ein EXECUTE-Recht auf dieses Schema, und was immer die Prozeduren durchführen (SELECT, INSERT, UPDATE, DELETE), erfordert keine weiteren Rechte – schon gar nicht auf den Tabellen, hier im Schema „Sales“, selber.
Und noch ein zweiter Ansatz wird hier ersichtlich: Das Denken an „Prozesse“ bzw. hier Applikationen. In vielen Datenbanken muss eine Applikation nicht wirklich auf alle Tabellen zugreifen. Spätestens sobald mehrere Applikationen mit einer Datenbank arbeiten, wird ersichtlich, dass das „Ordnungs-Konzept“ einem im Wege steht. Idealerweise erschafft man also für jede Applikation ein eigenes Schema, das genau die Prozeduren enthält, die diese verwenden soll. Für Ad-Hoc Zugriffe, die leider oft für Code-generatoren benötigt werden, kann man das auch mit Sichten machen. Und es hindert einen niemand daran, ein „gemeinsames Schema“ zu erschaffen, in dem Code (Prozeduren und Sichten) liegt, der von beiden verwendet wird.
Im Endeffekt kommt man so mit wirklich einer Handvoll Rechten aus, und genügt dennoch den Prinzipien „Least Privilege“ (Geringstmögliche Rechte) sowie „Separation of Duties“ (Funktionstrennung).
Hinweis zu Objektbesitzer und durchbrochene Besitzverkettung
Achtung: die Besitzverkettung kann auf allen Ebenen, d.h. Schema, Prozedur, Sicht oder Tabelle durchbrochen werden. Das passiert auch, wenn man den Besitzer einer Tabelle ändert, wie im Folgenden dargestellt.
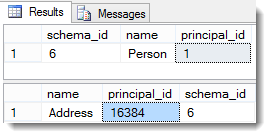
So kann man die Besitzer der beteiligten Schemas und Tabellen abfragen:


Eine Principal_id von NULL bedeutet, dass die Tabelle dem Schema_owner gehört. Das Schema „Person“ gehört dem dbo (principal_id=1)
Ändern des Besitzers der Tabelle:
ALTER AUTHORIZATION ON [Person].[Address] TO db_owner
An dieser Stelle ist die Besitzverkettung unterbrochen.
Und nicht nur das: auch sämtliche Schema-Berechtigungen werden dadurch zurückgesetzt!
Und so setzt man sie auf den Schema-Besitzer zurück – das ist besser, als den Besitzer explizit auf dbo (oder einen anderen Prinzipal) zu setzen:
![]()
Ergebnis:
AdventureWorks-Schema
korrigierte/sicherheits-optimierte Fassung
Nachdem das Konzept nun klar ist, versuchen wir es mal mit der AdventureWorks-Datenbank. Im Folgenden mein Vorschlag:

Die Sichten liegen nicht mehr zusammen mit Tabellen, damit ein SELECT-Recht auch wirklich nur Sichten betrifft. Neu ist das Schema „WebShop“, was beispielhaft für eine Applikation gedacht ist, die eben alle Prozeduren aufrufen und Sichten verwenden darf, die dafür programmiert worden sind. Das dbo-Schema ist jetzt leer und bestimmte Objekte, Log-Tabellen z.B. liegen im Admin-Schema. Man kann diese auch im dbo-Schema belassen, aber man muss bedenken, dass dieses immer als Default-Schema bei der Namesauflösung verwendet wird.
Ausführungskontext und durchbrochene Besitzverkettung
In manchen Szenarien kann eine durchbrochene Besitzverkettung auch gewollt sein. Um dennoch bestimmten Modulen Zugriff auf Daten im Zielschema zu gewähren, ohne das Zielschema selber mit Berechtigungen freizugeben, kann man mit der „EXECUTE AS-Klausel“ arbeiten. Die Umsetzung kann dann schematisch so aussehen:

Empfehlungen für Schema-Design
Im Folgenden einige Ansätze, wie man bei der Entscheidung für Schema-Design vorgehen kann.
Das Idealmaß wäre eine Struktur nach Prozess oder Anwendung (Unter Sicherheitsfachleuten auch „Rolle“)
Beispiel:
Process1.Objects, Process2.Objects, Data(1-n)
Weitere Beispiele für bestimmte Szenarien, wie sie Sarpedon Quality Lab® teilweise so auch seit Jahren in Kundenprojekten implementiert und in Schulungen gezeigt:
Standard OLTP
- Administration (Log-Tables etc.)
- DataPublic
- DataInternalOnly (if DB is used by different Apps, some public, some only for internal staff)
- (Web)App(1)
- (Web)App(2)
- Reporting (prefer own code-only DB!)
Data Processing (Cleansing etc.):
- Import (raw imported data)
- Dev (unfinalized code)
- Data (final, cleaned data)
- Access (Views/Procs for accessing the data)
DataWarehouses (Source for OLAP-Cubes)
- DimData (saves the old-fashion prefix „dim“/“fact“)
- FactData (…)
- vDim (for denormalized, star-schema-Dimension views)
- vFact (for the MeasureGroups)
- … other Housekeeping, Reporting, ETL -Schemas
Für lediglich interne Datenbanken kann man auch folgenden Ansatz verwenden:
- By Owner:
- DeveloperA.Objects
- DeveloperB.Objects
- By Structure:
- Subproject1.Objects
- Subproject2.Objects
Weitere Tipps:
- Anstelle “dbo” empfehle ich einen expliziten “User without Login“ anzulegen und als dedizierten Schema-Besitzer zu verwenden.
Die folgenden Schemas sind „backward compatibility schemas“, die man getrost löschen kann. Man kann sie nur löschen, wenn sie nicht verwendet werden, von daher gibt es da kein Risiko – und sie anzufangen zu verwende, davon rate ich natürlich auch ab.
- db_owner
- db_accessadmin
- db_securityadmin
- db_ddladmin
- db_backupoperator
- db_datareader
- db_datawriter
- db_denydatareader
- db_denydatawriter
Aufruf an Entwickler
An dieser Stelle vielen Dank fürs Lesen. Der erste Schritt ist damit getan: sich mit der Thematik Schema-Design überhaupt auseinanderzusetzen.
Ich würde mir wünschen, dass das auch zu einem Umdenken führt, und ich mehr durchdachte Schema-Verwendungen sehe. Und dazu kann auch eine sinnvolle logische Aufteilung aus Ordnungszwecken gehören – idealerweise in Kombination mit einem Zugriffsschema. Aber alles ist besser als sämtliche Programme direkt in C:Programme abzulegen – Unterordner sind dort ja auch Usus.
Happy Schema-Designing
Andreas
Acknowledgement
Special thanks to Jack Richins and Steven Gott from the Security Team in Redmond for reminding me of some aspects to add and allowing me to quote them in my article.

Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!