Das Prinzip des Need-to-know in SQL Server und Azure SQL
(Teil 2 meiner Artikelserie über Sicherheitsprinzipien bei Microsoft SQL Servern & Datenbanken)
Dieses Prinzip besagt, dass ein Benutzer nur Zugriff auf die Informationen haben darf, die seine Arbeitsfunktion erfordert, unabhängig von seiner Sicherheitsfreigabestufe oder anderen Berechtigungen.
Mit anderen Worten: Ein Benutzer braucht Berechtigungen UND ein Need-to-know. Und dieser Need-to-know ist streng an eine reale Anforderung für den Benutzer gebunden, um seine aktuelle Rolle zu erfüllen.
Wie Sie vielleicht an der Wortwahl erkennen können, wird das Need-to-know-Prinzip typischerweise in militärischen oder behördlichen Umgebungen durchgesetzt.
In nicht-militärischen Szenarien finden Sie manchmal auch eine etwas andere Beschreibung, die in abgeschwächter Form besagt, dass der Zugriff auf Daten regelmäßig überprüft werden muss, um sicherzustellen, dass Benutzer nur auf Daten zugreifen, die sie unbedingt aus legitimen Gründen benötigen. Dies ist eher eine Durchsetzung durch Vorschriften oder Regeln als durch Berechtigungen und kann im privaten Sektor ausreichend sein.
In der Informationstechnologie kann das Need-to-know durch die Verwendung einer mandatory access control (MAC)* sowie einer discretionary access control (DAC)* in Verbindung mit einem sekundären Kontrollsystem umgesetzt werden.
*Links zu weiterführender Literatur unter diesem Artikel
Hintergrund
SQL Server verwendet eine discretionary access control, da Besitzer von Objekten (und der höchste „Besitzer“ ist der sa-Account) Berechtigungen an Einzelpersonen weitergeben können. Ein MAC-basiertes System basiert traditionell auf einer Multi-Level-Security (MLS)-Betriebsumgebung, die mit Klassifizierungen von Objekten und Sicherheitsfreigaben von Benutzern arbeitet, und kann erweitert werden, um andere vorgeschriebene Faktoren wie ein Need-to-know zu erfordern.
In der Windows-Welt wird häufig ein MSL-Ansatz (Multiple Single-Level) verwendet: Im Wesentlichen werden verschiedene Datenebenen (z. B. „Secret“ und „Top Secret“) auf verschiedenen Servern oder sogar innerhalb verschiedener Umgebungen aufbewahrt.
Für das sekundäre Kontrollsystem gibt es keinen bestimmten Typ, der verwendet werden muss. Alles, was dieses Prinzip durchsetzen kann, ist gut.
Wenn kein sekundäres Kontrollsystem vorhanden ist, kann auch eine Überwachung (Auditing) des Zugriffs zum Einsatz kommen, um die Einhaltung der vorhandenen Need-to-Know-Protokolle zu kontrollieren. Auditing kann einen Verstoß nicht verhindern, aber es kann sicherstellen, dass er nicht unentdeckt und ohne Konsequenzen bleibt, welche auch immer das sein mögen.
Hinweis
Das Need-to-know-Prinzip kann deutlich mehr Sorgfalt und vor allem andere Vorgehensweisen erfordern als die oft verwendete diskretionäre oder rollenbasierte Zugriffskontrolle – wie unter Windows Server, dem Azure RBAC-System oder SQL Server. Dies hängt von der genauen Implementierung des Need-to-know-Faktors innerhalb des Systems ab. Wenn ein Benutzer die Job-Rolle wechselt, muss sichergestellt sein, dass der Need-to-know-Faktor sofort angepasst wird.
Allgemeines Beispielszenario
Eine Datenbank enthält Daten der technischen Spezifikationen aller Produkte, die das Unternehmen weltweit herstellt.
Die Daten können als „Öffentlich“, „Intern“ oder „Eingeschränkt“ klassifiziert werden.
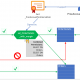
Einem Benutzer, Hoang, wurde die Leseberechtigung für alle Tabellen erteilt, die Daten für seine Arbeitsfunktion enthalten. Er hat die Freigabe für alles „Interne“ – einschließlich allem, was darunter liegt, was in diesem Fall „Öffentlich“ ist. Damit kann er also keine Tabellen lesen, die als „Eingeschränkt“ eingestuft sind.
Darüber hinaus hat er ein Need-to-know für Daten, die nur Daten eines bestimmten Projekts betreffen: „Kilimanjaro“.
Während also viele andere Projektdaten als „Intern“ gelten, kann er mit dem Need-to-know nur die sehen, die zu dem Projekt gehören, dem er zugeordnet ist: „Kilimanjaro“.
Andere Benutzer mit der gleichen Freigabe können ein anderes Need-to-know haben, je nach ihrer spezifischen Jobfunktion. Wie der Benutzer Ricardo in der Abbildung unten.

Tipp
Eine einfache Art, das Need-to-know-Prinzip darzustellen, ist die Überlegung, dass es im Grunde einen Filter auf einer sekundären Achse hinzufügt, zusätzlich zum bestehenden Zugriffskontrollsystem. Die genaue Mechanik ist Gegenstand der Implementierung.
Dieses einfache Beispiel geht davon aus, dass einzelne Datenobjekte innerhalb einer Datenbank unterschiedlich klassifiziert sind.
Hinweis
Die zusätzliche Steuerung über ein Need-to-know auf Daten, die als „öffentlich“ oder ähnlich eingestuft sind, ist nicht sinnvoll.
Beispielszenario militärischer Anwendungsfall
Das obige Beispiel mag seltsam anmuten, wenn Sie z. B. mit militärischen Umgebungen vertraut sind. In solchen werden sich „Top Secret“-Daten niemals auch nur in derselben Umgebung befinden wie „Secret“-Daten, geschweige denn „Unclassified“-Daten.
Ein vereinfachtes Szenario, das in solchen Umgebungen etwas realistischer ist, wird im Folgenden dargestellt. Ein bestimmter Benutzer Nathan hat zwar eine „Top Secret“-Clearance, würde aber gemäß seinem Need-to-know nur Daten zu „Alpha“ zu sehen bekommen.

Oder mit anderen Worten: Nur weil Nathan eine Top-Secret-Freigabe hat, heißt das nicht, dass er Top-Secret-Daten sehen kann. Er muss ein Need-to-know (und in der Tat zusätzliche Add-ons) haben. Andernfalls würden alle diese Daten redigiert werden.
Need-to-know im SQL-Bereich
SQL Server verfügt nicht über eine systemeigene Sicherheitsfunktion, die streng darauf ausgelegt ist, ein Need-to-know-Konzept durchzusetzen. Die SQL-Engine hat derzeit kein MAC-System integriert. Das Berechtigungssystem von SQL Server basiert auf Benutzeridentitäten und Eigentümern, die Berechtigungen erteilen können, und gilt daher als DAC-System (discretionary access control).
Dies ist aber nicht das Ende der Fahnenstange. Es gibt Möglichkeiten, dies zu einem Need-to-know-System zu erweitern.
Verwendung von Verschlüsselung
Eine Technik ist die Verwendung von Cell-Level-Verschlüsselung: Man kann Werte in bestimmten Zellen verschlüsseln, entweder auf Spalten- oder auf Zeilenebene (unter Verwendung einer benutzerdefinierten Logik), und der Entschlüsselungsschlüssel kann für mehrere Personen zugänglich gemacht werden und andere ausschließen.
In den Code-Schnipseln unten sehen wir, dass 2 Ärzten die gleichen minimalen Berechtigungen auf eine Tabelle namens „Patienten“ zugewiesen werden – einfach, indem man sie in die gleiche Datenbankrolle aufnimmt (als allgemeine Best Practice).

Im nächsten Schritt können wir sehen, dass jeder Arzt ein Zertifikat hat, das einen symmetrischen Schlüssel schützt – ein eindeutiger Schlüssel pro Zertifikat.

Dies ist dann der Inhalt des Systems:

Nun muss jeder Arzt nur noch Zugriff auf „seinen“ persönlichen Schlüssel haben. Hierfür reicht das Recht VIEW DEFINITION aus.

Dadurch kann jeder Arzt nur die Daten entschlüsseln, die mit seinem eigenen Schlüssel verschlüsselt wurden.

Hinweis
Die NULL-Werte in der „Symptoms“-Spalte werden für diejenigen Spalten zurückgegeben, bei denen die DecryptByKey-Funktion die Daten nicht mit dem/den aktuell geladenen Schlüssel(n) entschlüsseln kann. Die Daten dieser Spalten sind im Wesentlichen nur auf einer Need-to-know-Basis zugänglich.
Es ist auch möglich, mehreren Personae die Verwendung der gleichen Schlüssel zu ermöglichen. Dies kann durch Hinzufügen der Verschlüsselung durch zusätzliche Zertifikate zum gleichen symmetrischen Schlüssel erfolgen, wie hier gezeigt.

Das vollständige Beispiel steht als Download unter diesem Artikel zur Verfügung.
Theoretisch kann auch das Feature „Always Encrypted“ verwendet werden, um ein Need-to-know-System zu erzwingen, indem unterschiedliche Schlüssel für verschiedene Spalten vergeben werden. Das Prinzip ist, dass verschiedenen Benutzern die gleichen Rechte (SELECT, INSERT, UPDATE und oder DELETE) auf die Tabelle gewährt werden können, während sie über verschiedene Anwendungen mit Zugriff auf unterschiedliche Schlüssel auf die Tabellen zugreifen. Da die Schlüssel jedoch innerhalb des Prozesses zwischengespeichert werden, lässt sich diese Trennung nicht ohne Weiteres umsetzen und würde nur in Szenarien funktionieren, in denen verschiedene Anwendungsprozesse getrennt werden können, z. B. auf verschiedenen Rechnern.
Sicherheits-Hinweis
Man kann es nicht oft genug sagen: häufiger als man es sich wünscht, sehe ich Beispiele von Kreditkarten oder Sozialversicherungsnummern, die so gespeichert werden, dass die letzten 4 Ziffern im Klartext bleiben. (Berühmte Frage für Call-Center-Agenten, aber auch schlechte Schauspieler!) Tun Sie das nicht. Diese letzten Ziffern sind die zufälligen Teile dieser wichtigen Nummern. Die ersten Blöcke sind ziemlich statisch und nicht personalisiert.
Hier können Sie mehr darüber lesen, wie diese missbraucht werden können: How Apple and Amazon Security Flaws Led to My Epic Hacking | WIRED, What Can A Scammer Do With the Last 4 Digits of Your Social Security Number? | Consumer Boomer
Row Level Security für die Anwendung verwenden
Es gibt eine weitere Funktion innerhalb von SQL, die bei der Implementierung eines Need-to-know-Systems helfen kann: Wenn der Zugriff auf bestimmte Anwendungen beschränkt werden kann (und Benutzer keine direkte Verbindung zur Datenbank herstellen können), kann Row Level Security (RLS) verwendet werden, um ein solches System zu implementieren.
Das Konzept besteht hier darin, Informationen in der Datenbank zu speichern, die von einer speziellen Tabellenwertfunktion ausgelesen werden und gemeinsam mit Informationen aus dem aktuellen Benutzerkontext zu verwenden werden, um einen Filter auf die Abfrage anzuwenden. Dies alles geschieht, ohne dass die aufrufende Anweisung umgeschrieben werden muss, da diese Funktion über eine Sicherheitsfunktion an die Tabelle gebunden ist, die gefiltert werden soll.
Sicherheits-Hinweis
Row Level Security ist keine Sicherheitsfunktion, sondern eine Programmierbarkeitsfunktion, die zur Implementierung von Sicherheitsmechanismen verwendet werden kann, wenn sichergestellt werden kann, dass Benutzer die Datenbank nicht direkt abfragen können. Es ist wichtig, dies sicherzustellen. Außerdem kann es nicht zum Schutz vor Datenbankadministratoren oder sogar Entwicklern auf derselben Datenbank verwendet werden.
Hier sehen Sie, wie eine solche Funktion und Sicherheitsrichtlinie aussehen kann:

Bei der Abfrage der Tabelle, in diesem Fall „Patienten“, ändert SQL Server den Abfrageplan, fügt die Funktion ein und wendet die Filterung in diesem Fall basierend auf der SID der aktuellen Benutzer an, die in einer Tabelle „StaffDuties“ gespeichert ist.

Das bedeutet, dass nur das Personal, das in demselben Flügel arbeitet, in dem sich der Patient befindet, auf die Daten des Patienten zugreifen kann – unabhängig von den allgemeinen Zugriffsberechtigungen, wie unten abgebildet.

Code-Beispiele finden Sie in der Online-Dokumentation: Row-Level Security – SQL Server | Microsoft Docs.
Ähnliches kann durch die Verwendung von benutzerdefinierten Stored Procedures mit entsprechender Logik darin erreicht werden. Auch hier gilt: Es kann nur als eine Annehmlichkeit auf Anwendungsebene gesehen werden, nicht aber als Grundlage eines Need-to-know-Systems.
Es kann auch durchaus sinnvoll sein, RLS und Always verschlüsselt zu kombinieren, um Need-to-know auch bei Admin-Zugriff zu erzwingen.
Auch dies sind nur einige Beispiele dafür, wie das Need-to-Know-Prinzip umgesetzt werden kann. Wie gesagt, es gibt nicht die eine goldene Regel in diesem Bereich.
Happy securing
Andreas
Vielen Dank an meine Reviewer:
Adrian Rupp, Senior Program Manager in SQL Security mit speziellen Kenntnissen in militärischen Szenarien
Jakub Szymaszek, Principal Program Manager in SQL Security zum Thema Verschlüsselung
Rohit Nayak, Senior Program Manager in SQL Security
Dilli Dorai Minnal Arumugam, Principal Software Engineer in Data-Governance
Ressourcen
- Wikipedia: https://en.wikipedia.org/wiki/Need_to_know
- Deutscher Artikel zum „Erforderlichkeitsprinzip”: https://de.wikipedia.org/wiki/Need-to-know-Prinzip
- Mandatory access control – Wikipedia
- Multilevel security – Wikipedia
- Multiple single-level – Wikipedia
- Mandatory Integrity Control – Win32 apps | Microsoft Docs
- Classified information – Wikipedia
- Discretionary access control – Wikipedia
- Sanitization (classified information) – Wikipedia
- What is Azure role-based access control (Azure RBAC)? | Microsoft Docs
- Always Encrypted – SQL Server | Microsoft Docs
- Always Encrypted with secure enclaves – SQL Server | Microsoft Docs
- Encrypt a Column of Data – SQL Server & Azure Synapse Analytics & Azure SQL Database & SQL Managed Instance | Microsoft Docs
- Row-Level Security in SQL Server